13 Refined Results
Reviewed the current literature on selection of candidate learners to understand why TMLE was not achieving best coverage (particularly double cross-fitted version).
Donsker class and Smooth learner
- Donsker class: uniform convergence of empirical processes, generalization performance of learning algorithms, reduction of the risk of overfitting
- Smooth learner: algorithm producing differentiable and continuous functions. Non-smooth are often sensitive to small changes in the training data and can overfit easily.
- Logistic regression: smooth learner, belongs to the Donsker class
- MARS: piecewise smooth learner, classification of MARS into the Donsker class is not straightforward
- LASSO: produces a continuous function, can be considered piecewise smooth or quasi-smooth; can belong to the Donsker class
- XGBoost: non-smooth learner, classification of XGBoost into the Donsker class is not straightforward
Super Learner guidelines suggested using diverse learners, including both smooth and non-smooth learners. The main idea behind this recommendation was to leverage the strengths of different learners and allow them to compensate for each other’s weaknesses. By combining diverse base learners, Super Learner aims to improve the overall generalization performance of the ensemble. However, researchers and practitioners have gained a deeper understanding of the implications of including non-smooth learners in the ensemble. The potential downsides of non-smooth learners, such as high variance and overfitting, are now better understood. As a result, more emphasis may be placed on carefully selecting and tuning non-smooth learners to minimize their potential negative impact on the ensemble’s performance.
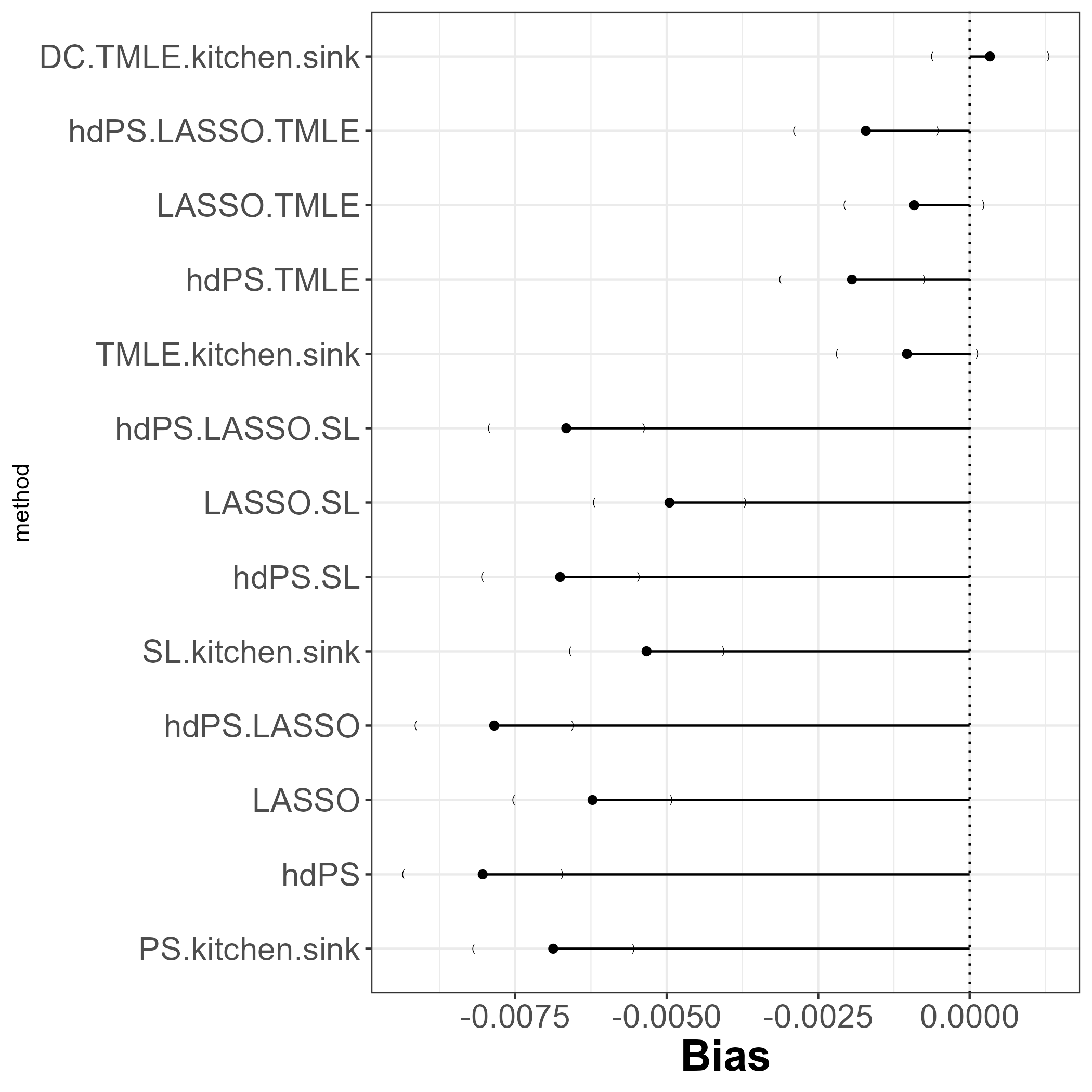
13.1 Bias
SLrepresents those where super learner was used with the following 3 candidate learners- Logistic regression
- MARS (Multivariate Adaptive Regression Splines)
- LASSO
TMLErepresents those where TMLE was usedDCrepresents double cross-fit.
XGBoost omitted
DCversion ofTMLE(kitchen sink) associated with least bias!- Non-super learner methods remains the same (results did not change).
- Same super learner used for
SLandTMLEmethods.
13.2 MSE
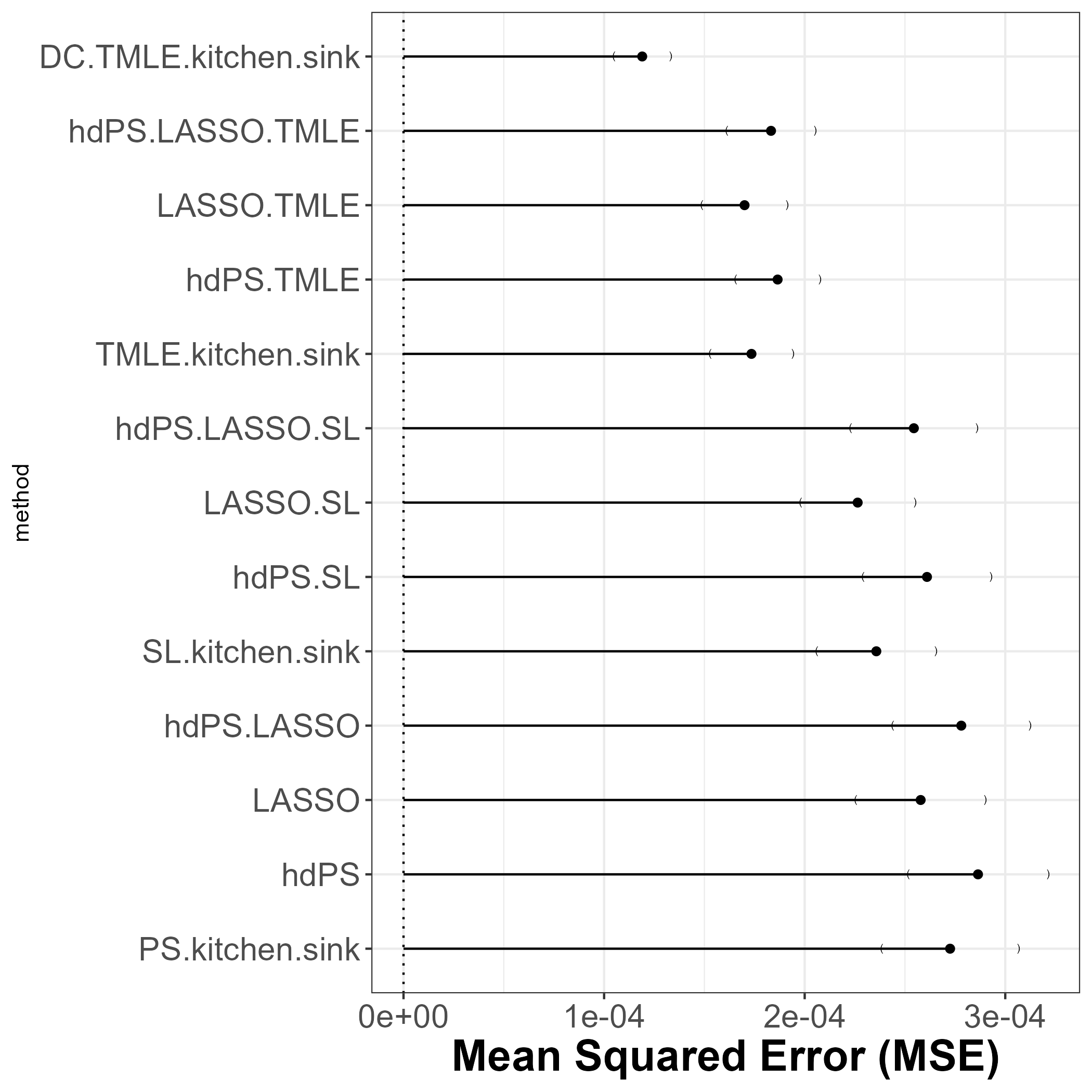
DCversion ofTMLE(kitchen sink) associated with least MSE!
13.3 Relative Error
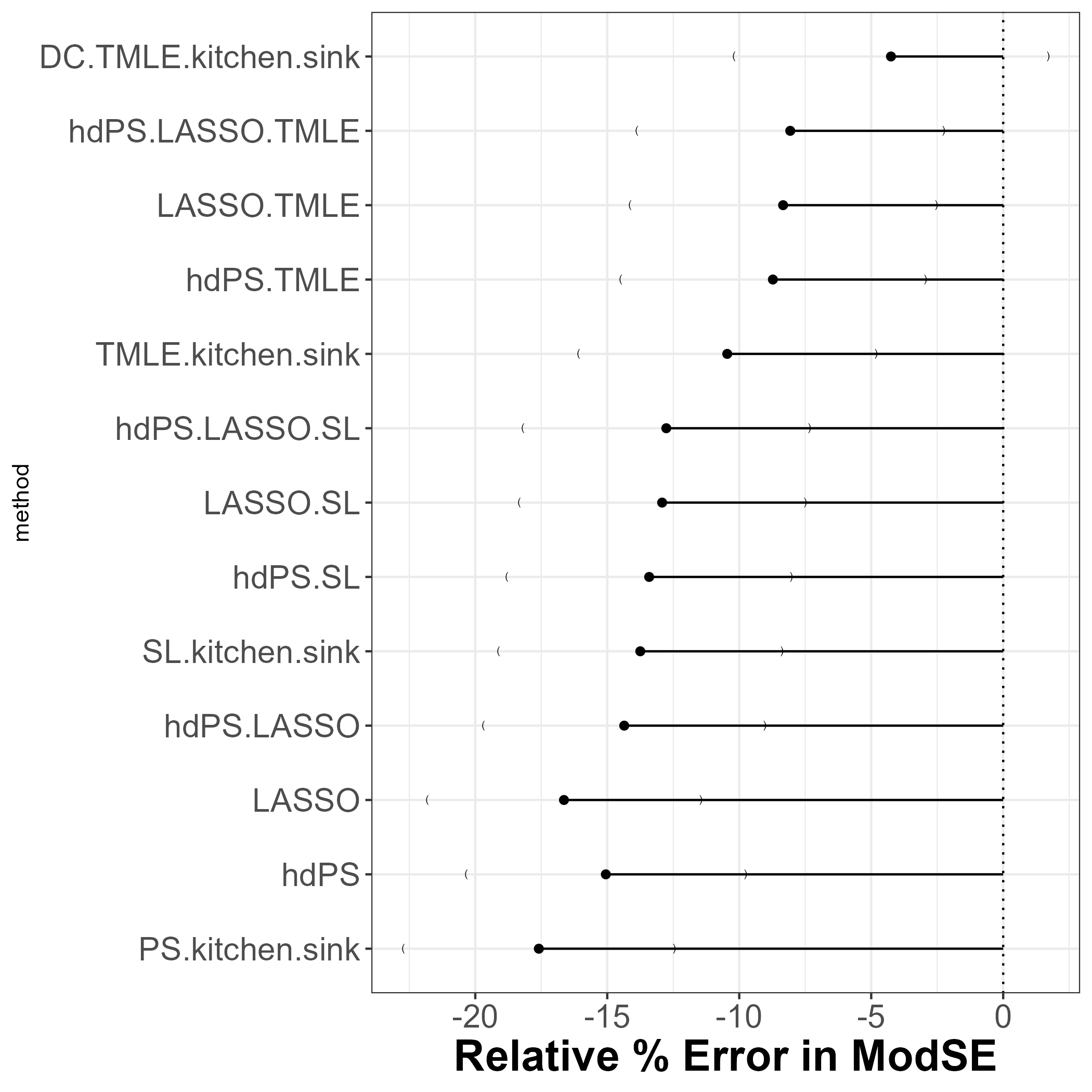
DCversion ofTMLE(kitchen sink) associated with least relative error in model SE estimation!
13.4 Coverage
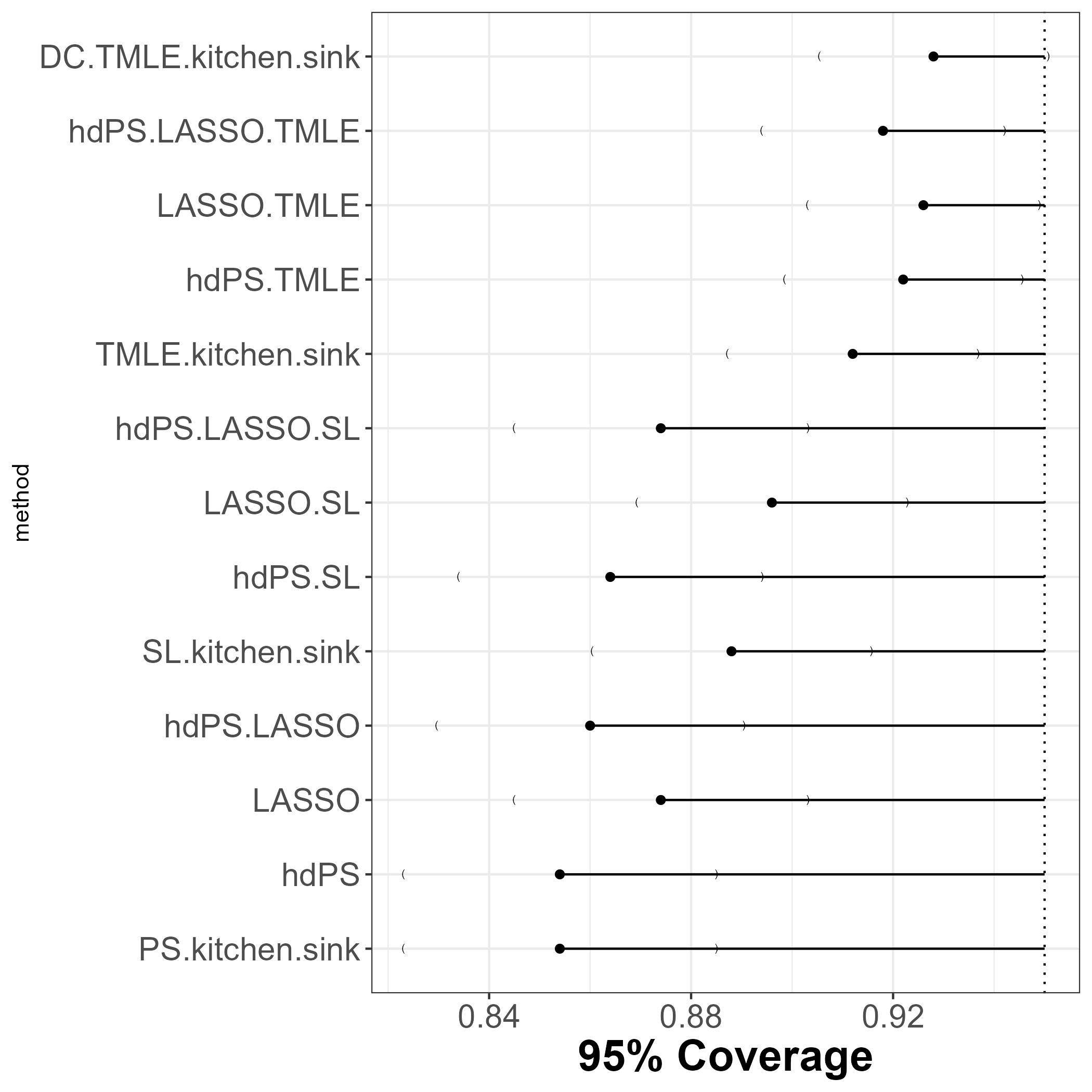
DCversion ofTMLE(kitchen sink) associated with coverage closest to nominal!
13.5 Bias eliminated coverage
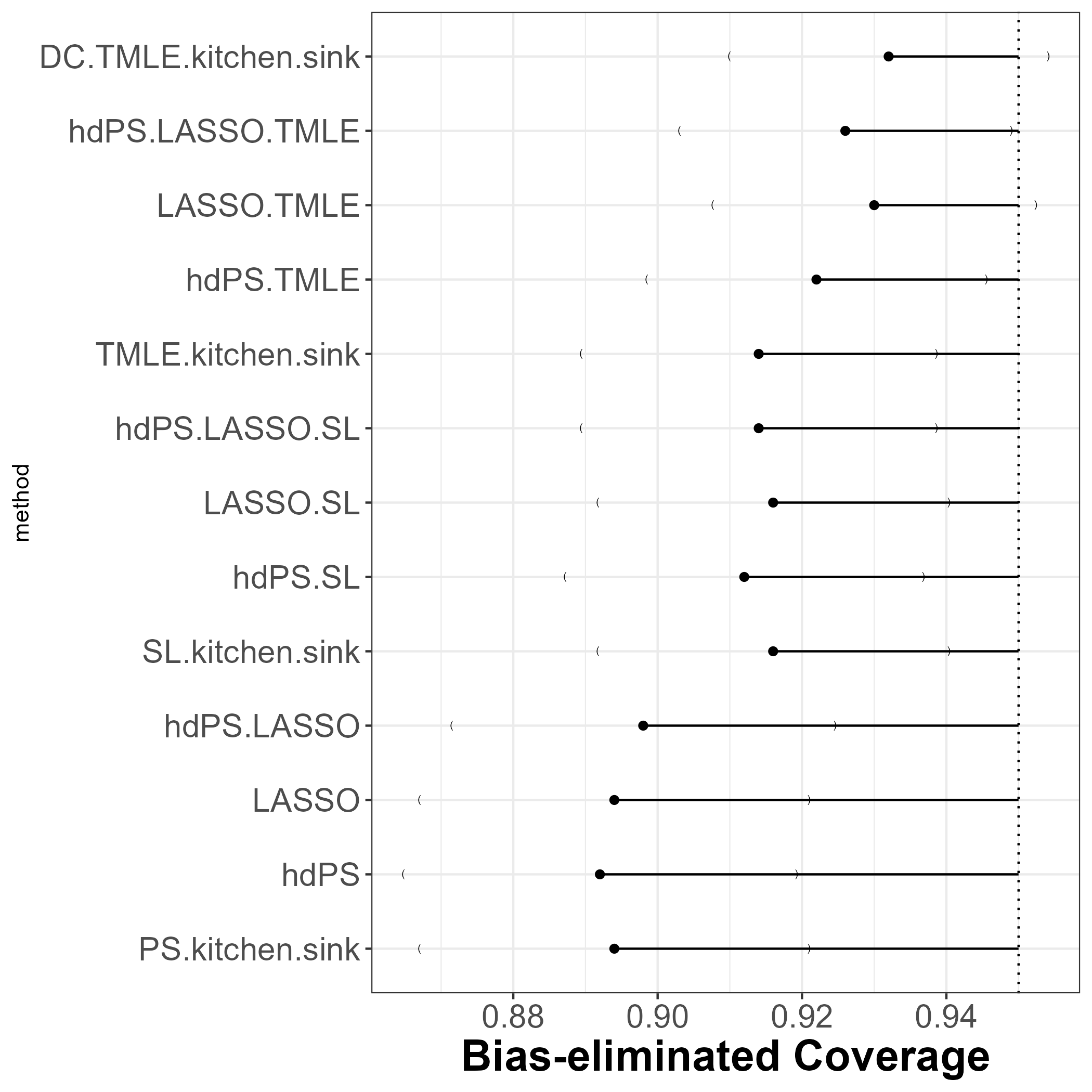
DCversion ofTMLE(kitchen sink) associated with bias eliminated coverage closest to nominal!
13.6 More Details
Review more detailed simulation results conducted:
| Analysis strategy | Outcome Model Specification |
|---|---|
| Firth regression | The same |
| Stabilized weights | The same |
| Various outcome model specification | |
| No covariate adjustment | |
| Just investigator-specified covariate adjustment | |
| Adjustment of only those investigator-specified covariates that are imbalanced (SMD > 0.1) | |
| Adjustment of only those covariates that are imbalanced (SMD > 0.1; investigator-specified or recurrence) | |
| Adjustment of all covariates (investigator-specified or recurrence) |
(Firth 1993; Austin and Stuart 2015)
All of the aove figures are based on adjustment of all covariates (investigator-specified or recurrence) in the outcome model.
ShinyApp
Look at the ShinyApp for additional details!