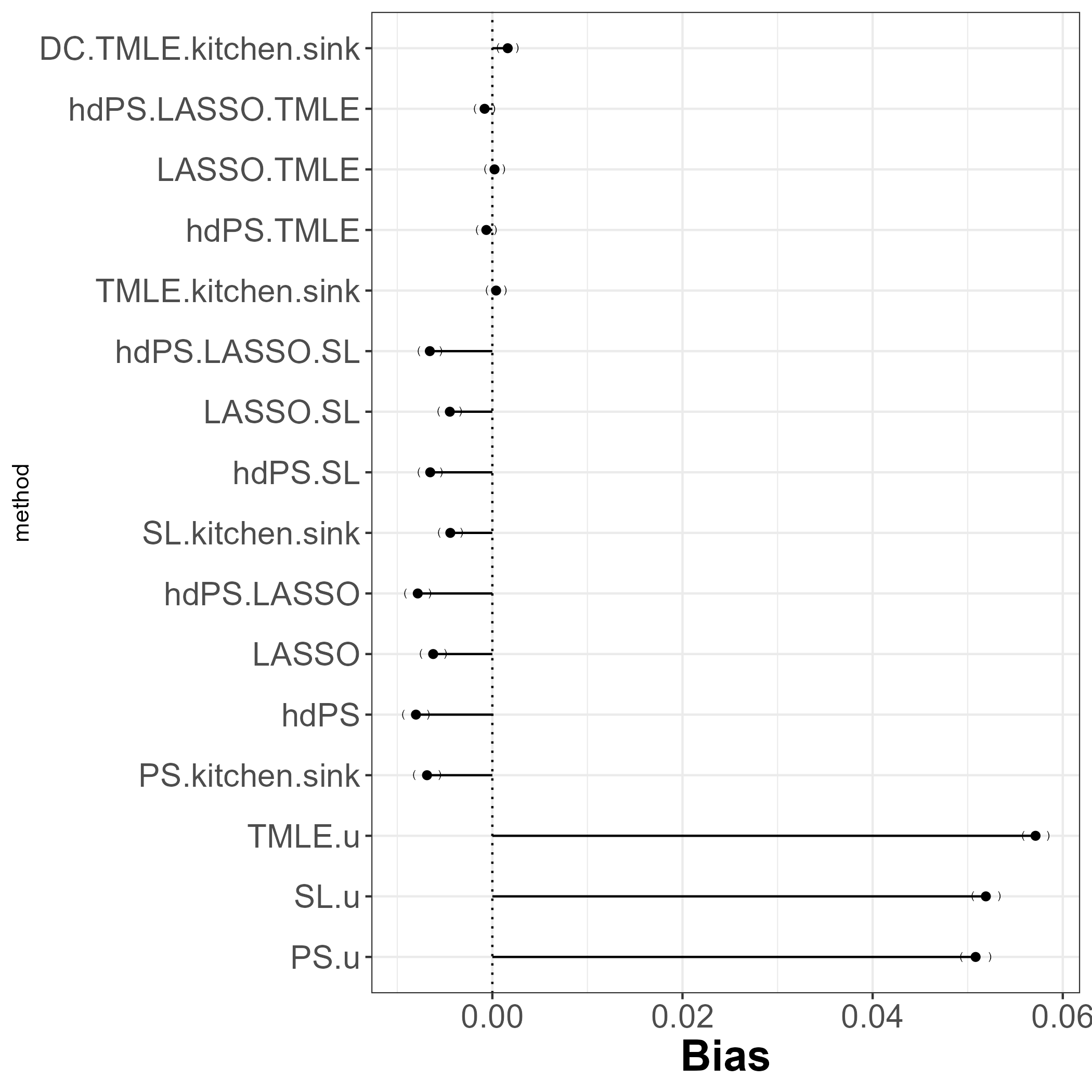
12 Results
12.1 Bias
urepresents those where no proxies are utilizedSLrepresents those where super learner was used with the following 4 candidate learners- Logistic regression
- MARS (Multivariate Adaptive Regression Splines)
- LASSO
- XGBoost (Extreme Gradient Boosting)
TMLErepresents those where TMLE was usedDCrepresents double cross-fit.
Same super learner used for SL and TMLE methods.
Tip
Clearly using proxies improve bias estimates
12.2 Bias (used proxies)
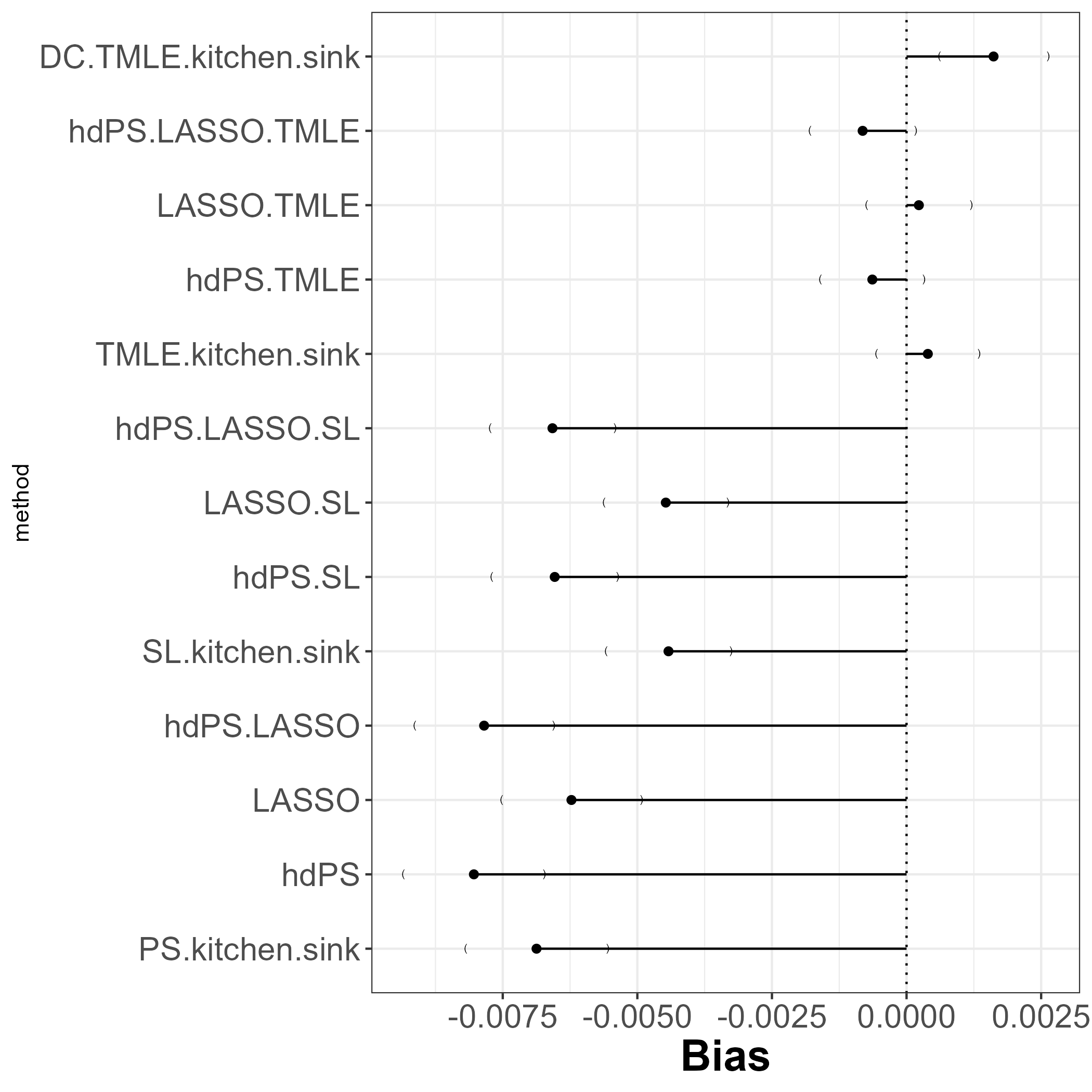
SLmethods seem to have negligible improvements overnon-SLmethods in terms of bias.TMLEmethods winning in terms of bias.
12.3 MSE
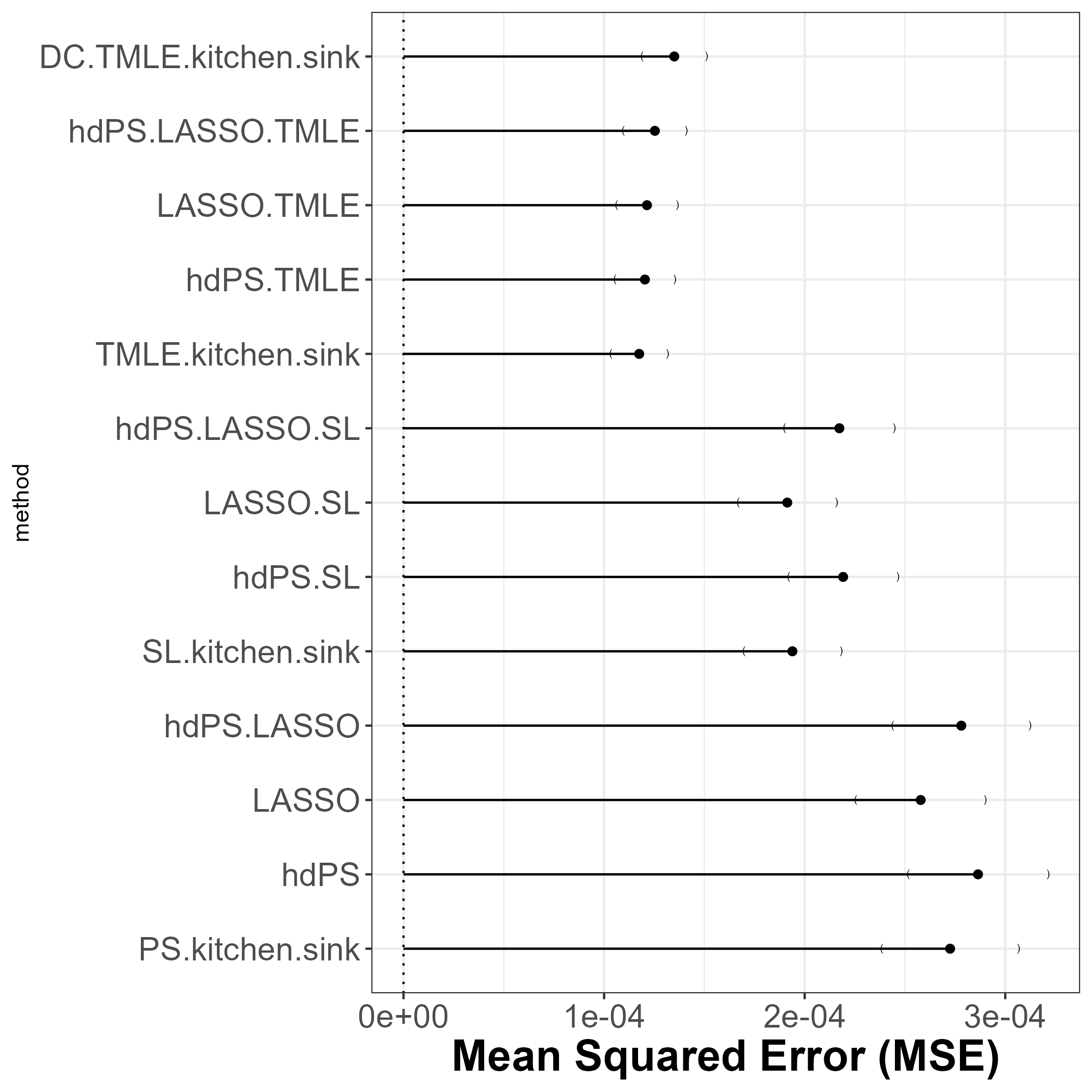
TMLEmethods winning in terms of MSE.
12.4 Relative Error
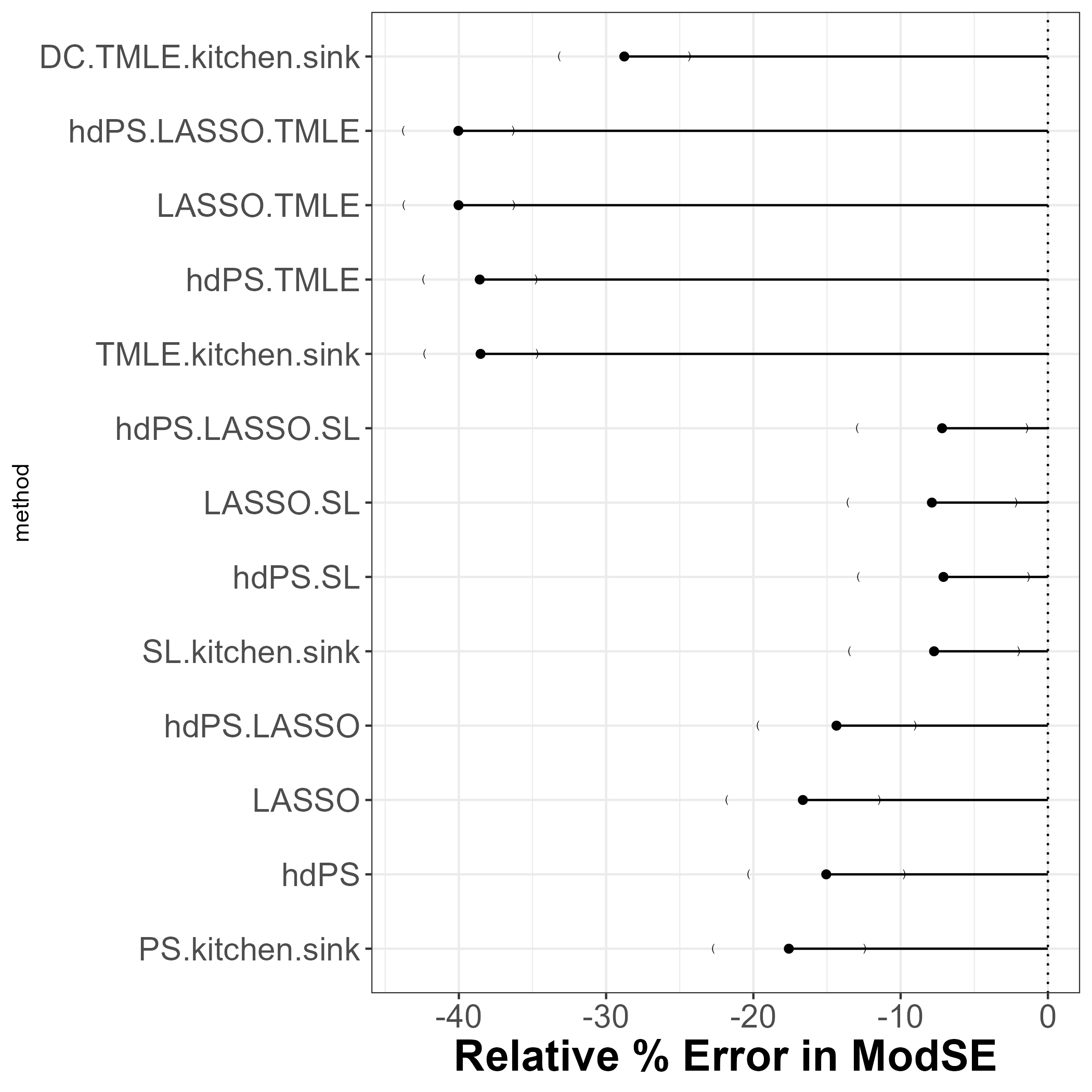
TMLEmethods are have worse relative % error in Model SE estimation.SLmethods are winners.
12.5 Coverage
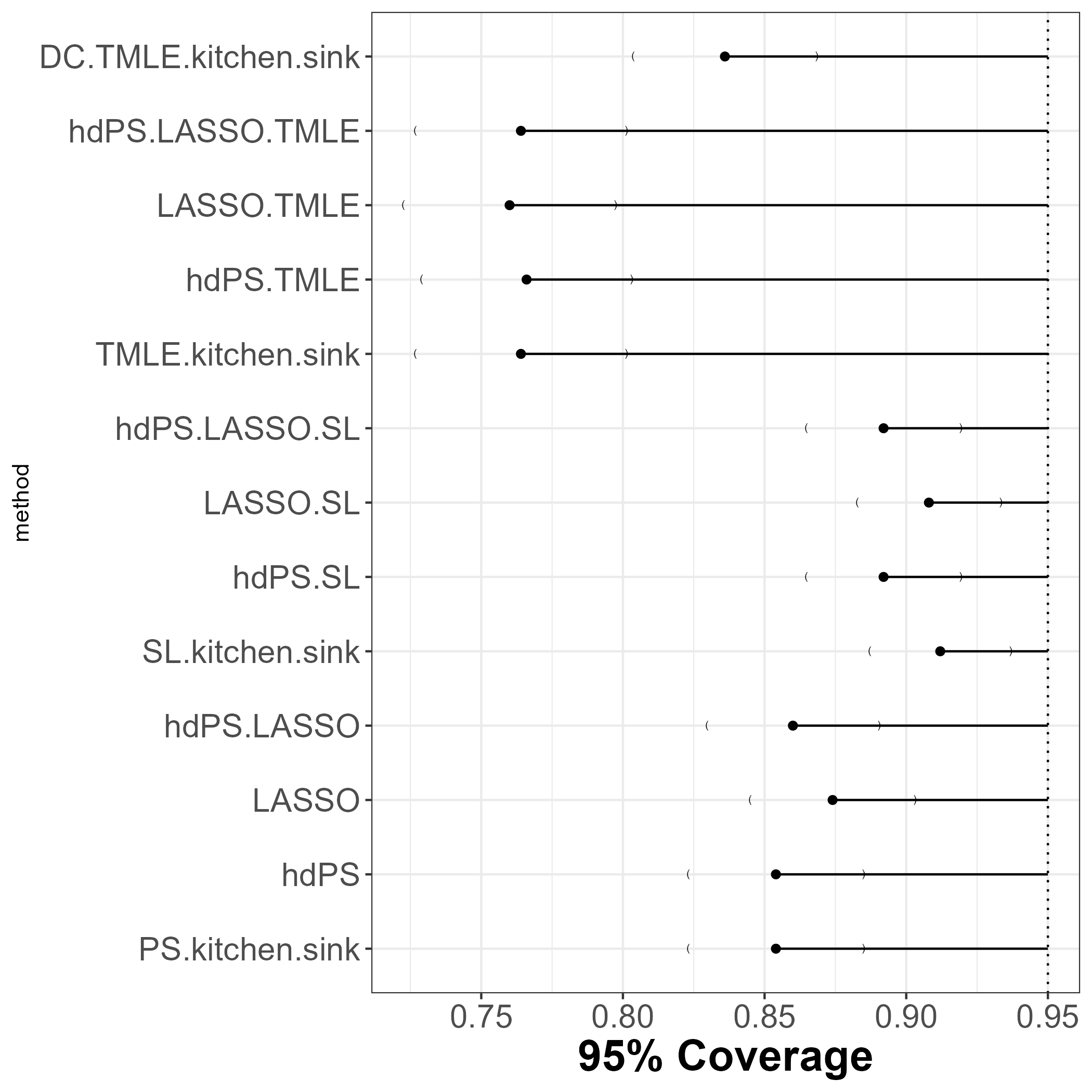
TMLEmethods are have worse 95% coverage (below 85%).SLmethods are winners.- But some of these methods were biased, so hard to compare.
12.6 Bias eliminated coverage
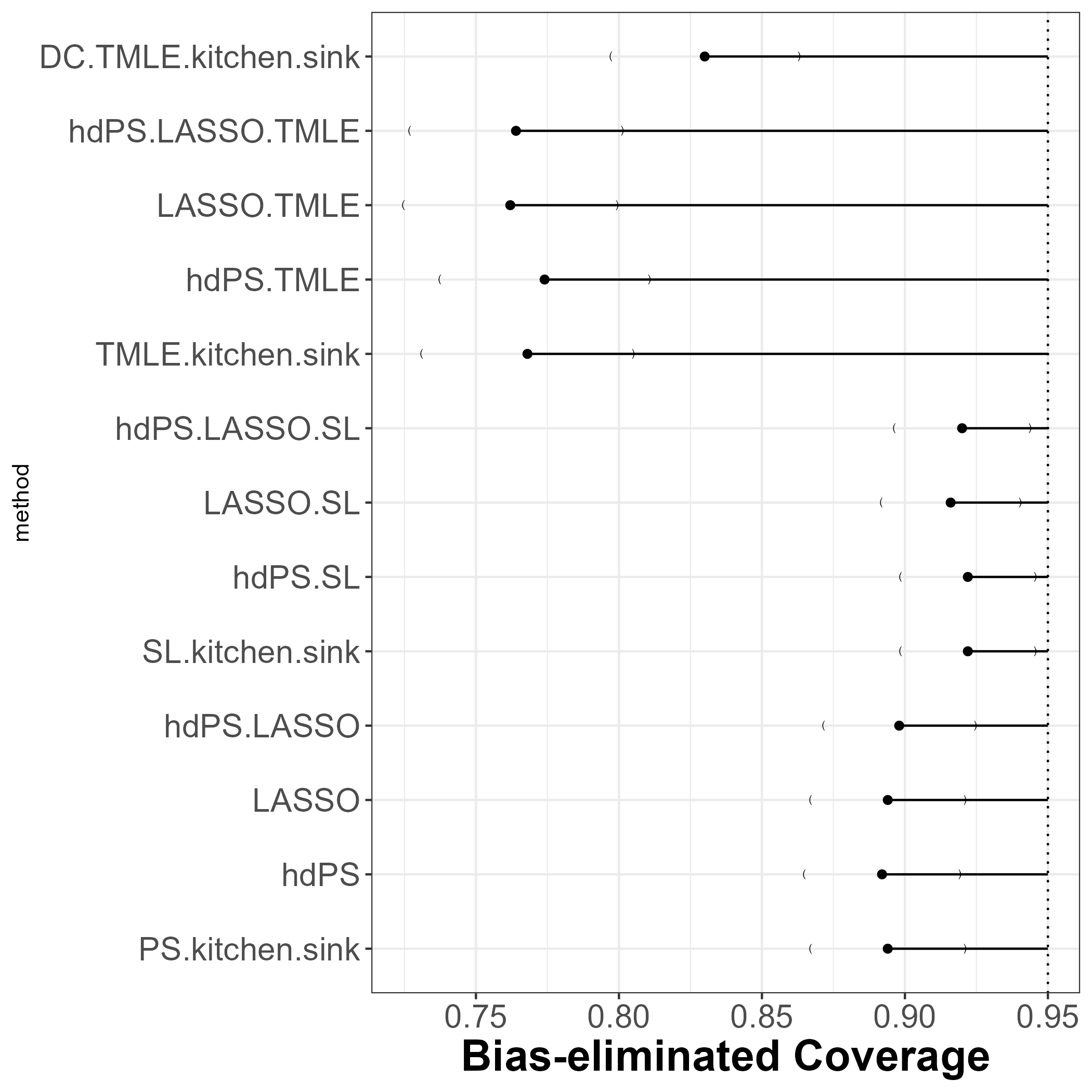
TMLEmethods are have worse 95% bias eliminated coverage (below 85%).