Chapter 11 Critical Appraisal
- Watch the video describing this chapter
Was always skeptical about the deluge of ML papers coming out during COVID. Critical appraisal of a Machine Learning paper is an important aspect of modern medicine evidence analysis. pic.twitter.com/8yvnsVbL4L
— vishnu v y (@vishnuvy) June 6, 2021
Given the popularity of ML and AI methods, it is important to be able to critically appraise a paper that reports ML / AI analyses results.
11.1 Existing guidelines
Liu et al. (2020) and Rivera et al. (2020) provided the CONSORT-AI and SPIRIT‑AI Extensions. Vinny et al. (2021) reported a number of ways to critically appraise an article that analysed the data using an ML approach.
11.2 Key considerations
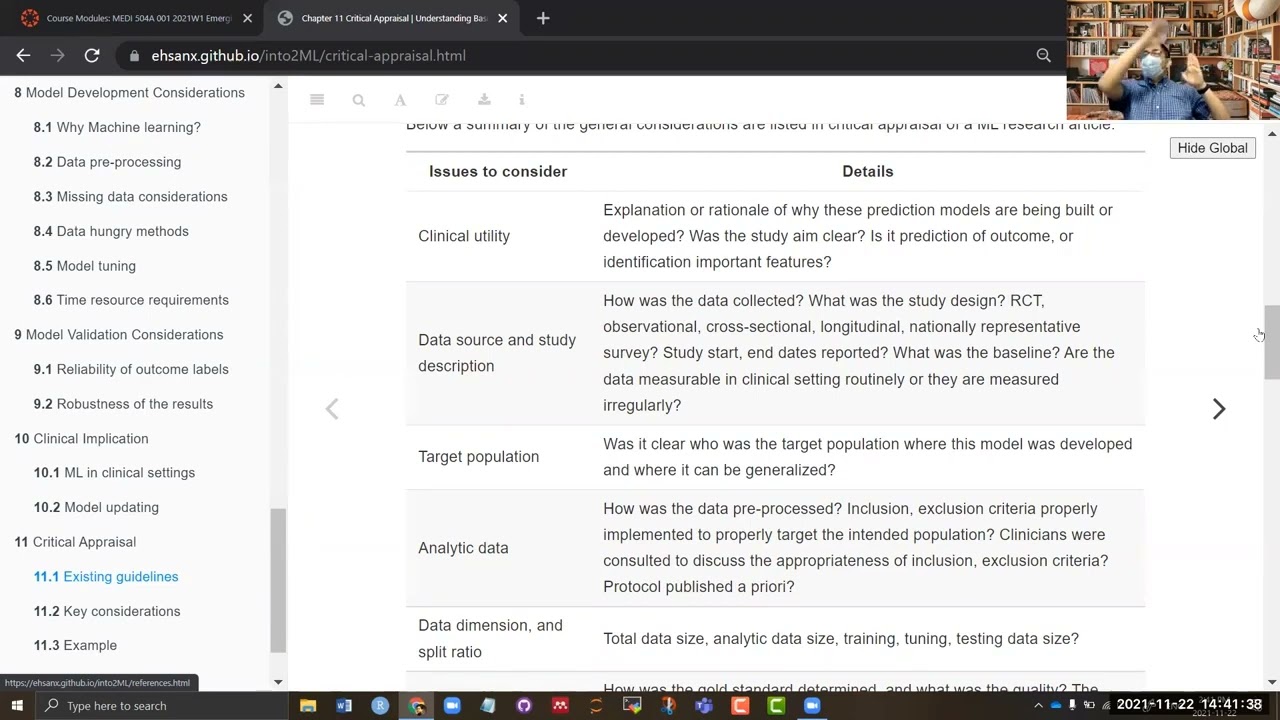
Below a summary of the general considerations are listed in critical appraisal of a ML research article.
| Issues to consider | Details |
|---|---|
| Clinical utility | Explanation or rationale of why these prediction models are being built or developed? Was the study aim clear? Is it prediction of outcome, or identification important features? |
| Data source and study description | How was the data collected? What was the study design? RCT, observational, cross-sectional, longitudinal, nationally representative survey? Study start, end dates reported? What was the baseline? Are the data measurable in clinical setting routinely or they are measured irregularly? |
| Target population | Was it clear who was the target population where this model was developed and where it can be generalized? |
| Analytic data | How was the data pre-processed? Inclusion, exclusion criteria properly implemented to properly target the intended population? Clinicians were consulted to discuss the appropriateness of inclusion, exclusion criteria? Protocol published a priori? |
| Data dimension, and split ratio | Total data size, analytic data size, training, tuning, testing data size? |
| Outcome label | How was the gold standard determined, and what was the quality? The prediction of such outcome clinically relevant? |
| Features | How many covariates or features used? How were these variables selected? Subject area experts consulted in selection and identification of some or all of these variables? Any of these variables transformed or dichotomized or categorized or combined? A table of baseline characteristics of the subjects, stratified by the outcome labels presented? |
| Missing data | Were the amount of missing observations reported? Any explanation of why they were missing? How were the missing values handles? Complete case or multiple imputation? |
| ML model choice | Rationale of the ML model choice (logistic, LASSO, CART or extensions, ensemble, or others)? Model specification? Additive, linear or not? Amount of data adequate given the model complexity (number of parameters)? |
| ML model details | Details about ML model and implementation reported? Model fine tuned? Model somehow customized? Hyperparameters provided? |
| Optimism or overfitting | What method was used to address these issues? What measures of performances were used? Was there any performance gap (between tuned model vs internal validation model)? Model performance reasonable, or unrealistic? |
| Generalizability | External validation data present? Model was tested in real-world clinical setting? |
| Reproducibility | repeatable and reproducible? These can be in 3 levels (i) model (ii) code (iii) data or their combinations. Software code provided? Which software and version was used? Was the computing time reported? |
| Interpretability | Clinicians were consulted? Results were interpreted in collaboration with clinicians and subject area experts? Model results believable, interpretable? |
| Subgroup | Clinically important subgroups considered? |
11.3 Example
- Download the article by Antman et al. (2000) (link). Try to identify how many of the above key considerations they have reported in the process of developing a risk score?
- OpenSafely article in Nature: let’s discuss research goal.
BIGGEST TABLE 2 FALLACY EVER#EpiTwitter, do you remember the discussions around the @OpenSafely Williamson @nature study this summer?
— Olivier Berruyer (@OBerruyer) October 12, 2020
The French @gouvernementFR admitted they used this study's Table 2 to withdraw protections from 100.000s of workers at risk of severe #COVID19! pic.twitter.com/qpllRe90N7
11.4 Exercise
Find an article in the medical literature (published in a peer-reviewed journal, could be related to the area that you work on, or are interested in) that used a machine learning method to build a clinical prediction model (here is an example). Critically appraise that article.
In this chapter, we will talk about how to critically appraise an article analyzing data using machine learning methods.