Chapter 6 Importing NHANES to R
This is a short instruction document of how to get NHANES dataset from the US CDC site to your RStudio environment. Once we bring the dataset into RStudio, the next step is to think about creating analytic dataset.
6.1 NHANES Dataset
National Center for Health Statistics (NCHS) conducts National Health and Nutrition Examination Survey (NHANES) (CDC,NCHS (2018)). These surveys are designed to evaluate the health and nutritional status of U.S. adults and children. These surveys are being administered in two-year cycles or intervals starting from 1999-2000. Prior to 1999, a number of surveys were conducted (e.g., NHANES III), but in our discussion, we will mostly restrict our discussions to `continuous NHANES’ (e.g., NHANES 1999-2000 to NHANES 2017-2018).
Witin the CDC website, continuous NHANES data are available in 5 categories:
- Demographics
- Dietary
- Examination
- Laboratory
- Questionnaire6.2 Accessing NHANES Data
In the following example, we will see how to download ‘Demographics’ data, and check associated variable in that data.
6.2.1 Accessing NHANES Data Directly from the CDC website
NHANES 1999-2000 and onward survey datasets are publicly available at wwwn.cdc.gov/nchs/nhanes/.

- Step 1: Say, for example, we are interested about NHANES 2015-2016 surveys. Clicking the associated link in the above Figure gets us to the page for the cirresponding cycle (see below).

- Step 2: There are various types of data available for this survey. Let’s explore the demographic information from this clycle. These data are mostly available in the form of SAS `XPT’ format (see below).

- Step 3: We can download the XPT data in the local PC folder and read the data into R as as follows:
# install.packages("SASxport")
require(SASxport)
library(foreign)
DEMO <- read.xport("SurveyData\\DEMO_I.XPT")##
## Attaching package: 'foreign'## The following objects are masked from 'package:SASxport':
##
## lookup.xport, read.xport- Step 4: Once data is imported in RStudio, we will see the
DEMOobject listed under data window (see below):
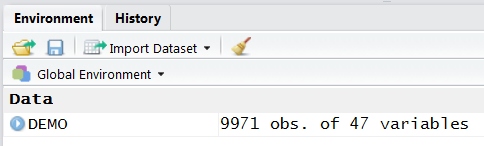
- Step 5: We can also check the variable names in this
DEMOdataset as follows:
names(DEMO)## [1] "SEQN" "SDDSRVYR" "RIDSTATR" "RIAGENDR" "RIDAGEYR" "RIDAGEMN"
## [7] "RIDRETH1" "RIDRETH3" "RIDEXMON" "RIDEXAGM" "DMQMILIZ" "DMQADFC"
## [13] "DMDBORN4" "DMDCITZN" "DMDYRSUS" "DMDEDUC3" "DMDEDUC2" "DMDMARTL"
## [19] "RIDEXPRG" "SIALANG" "SIAPROXY" "SIAINTRP" "FIALANG" "FIAPROXY"
## [25] "FIAINTRP" "MIALANG" "MIAPROXY" "MIAINTRP" "AIALANGA" "DMDHHSIZ"
## [31] "DMDFMSIZ" "DMDHHSZA" "DMDHHSZB" "DMDHHSZE" "DMDHRGND" "DMDHRAGE"
## [37] "DMDHRBR4" "DMDHREDU" "DMDHRMAR" "DMDHSEDU" "WTINT2YR" "WTMEC2YR"
## [43] "SDMVPSU" "SDMVSTRA" "INDHHIN2" "INDFMIN2" "INDFMPIR"- Step 6: We can open the data in RStudio in the dataview window (by clicking the
DEMOdata from the data window). The next Figure shows only a few columns and rows from this large dataset. Note that there are some values marked as “NA”, which represents missing values.
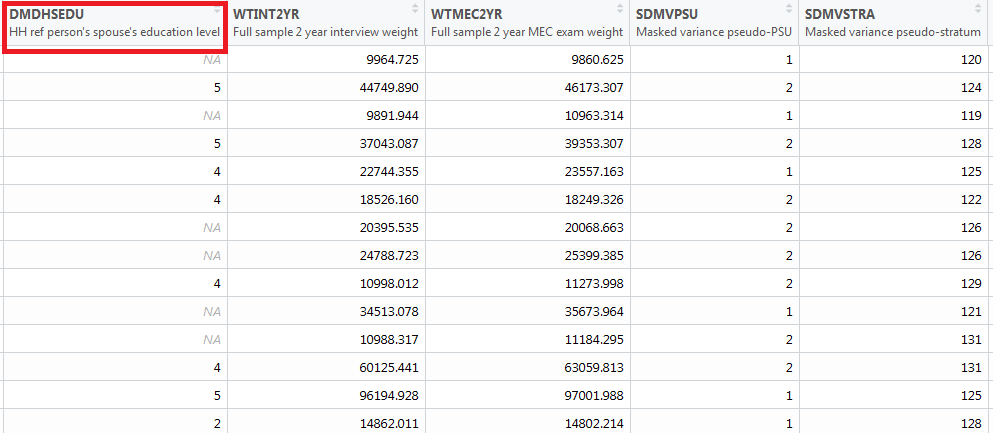
- Step 7: There is a column name associated with each column, e.g.,
DMDHSEDUin the first column in the above Figure. To understand what the column names mean in this Figure, we need to take a look at the codebook. To access codebook, click the'DEMO|Doc'link (in step 2). This will show the data documentation and associated codebook (see the next Figure).
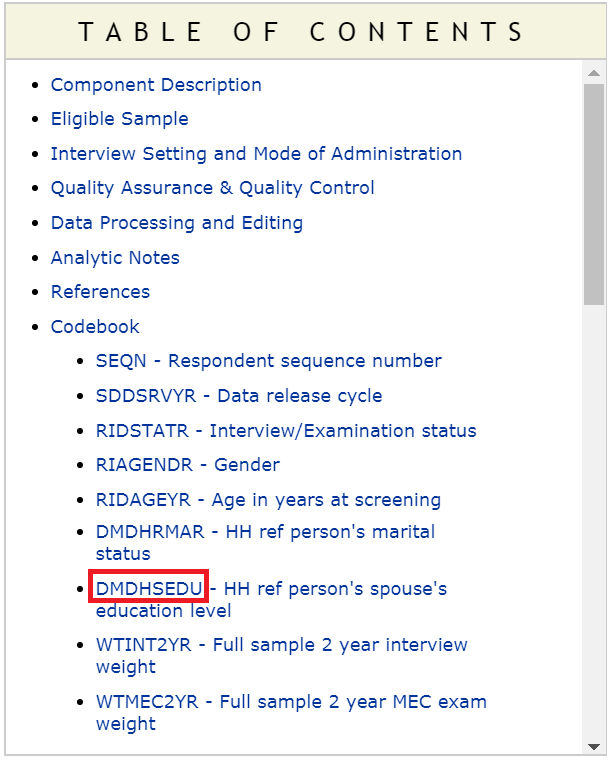
- Step 8: We can see a link for the column or variable
DMDHSEDUin the table of content (in the above Figure). Clicking that link will provide us further information about what this variable means (see the next Figure).
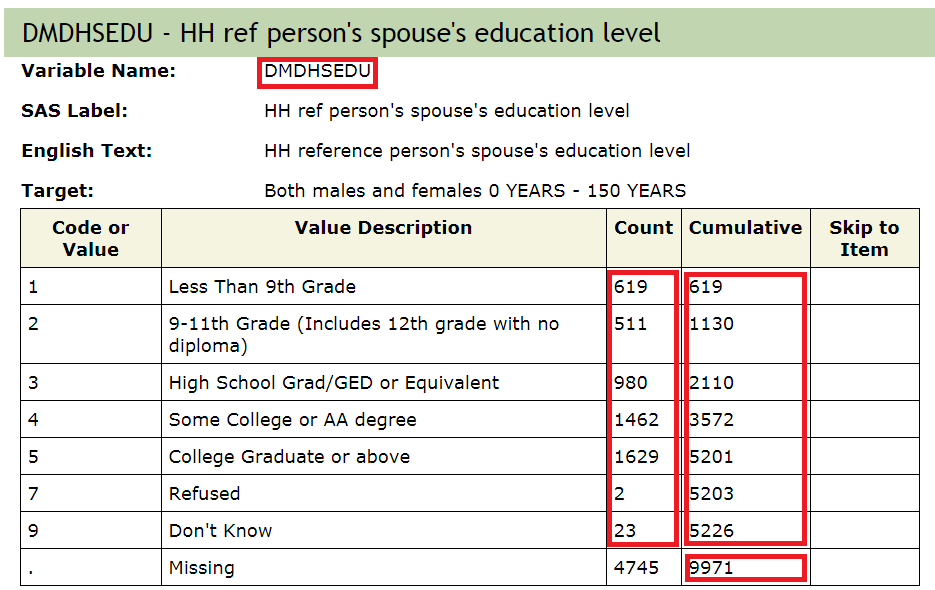
- Step 9: We can assess if the numbers reported under count and cumulative (from the above Figure) matches with what we get from the
DEMOdata we just imported (particularly, for theDMDHSEDUvariable):
table(DEMO$DMDHSEDU)##
## 1 2 3 4 5 7 9
## 619 511 980 1462 1629 2 23cumsum(table(DEMO$DMDHSEDU))## 1 2 3 4 5 7 9
## 619 1130 2110 3572 5201 5203 5226length(is.na(DEMO$DMDHSEDU))## [1] 99716.2.2 Accessing NHANES Data Using R Packages
6.2.2.1 nhanesA
nhanesA provides a convenient way to download and analyze NHANES survey data.
#install.packages("nhanesA")
library(nhanesA)- Step 1: Witin the CDC website, NHANES data are available in 5 categories
- Demographics (
DEMO) - Dietary (
DIET) - Examination (
EXAM) - Laboratory (
LAB) - Questionnaire (
Q)
- Demographics (
To get a list of available variables within a datafile, we run the following command (e.g., we check variable names within DEMO data):
library(nhanesA)
nhanesTables(data_group='DEMO', year=2015)## Data.File.Name Data.File.Description
## 1 DEMO_I Demographic Variables and Sample Weights- Step 2: We can obtain the summaries of the downloaded data as follows (see below):
demo <- nhanes('DEMO_I')
names(demo)## [1] "SEQN" "SDDSRVYR" "RIDSTATR" "RIAGENDR" "RIDAGEYR" "RIDAGEMN"
## [7] "RIDRETH1" "RIDRETH3" "RIDEXMON" "RIDEXAGM" "DMQMILIZ" "DMQADFC"
## [13] "DMDBORN4" "DMDCITZN" "DMDYRSUS" "DMDEDUC3" "DMDEDUC2" "DMDMARTL"
## [19] "RIDEXPRG" "SIALANG" "SIAPROXY" "SIAINTRP" "FIALANG" "FIAPROXY"
## [25] "FIAINTRP" "MIALANG" "MIAPROXY" "MIAINTRP" "AIALANGA" "DMDHHSIZ"
## [31] "DMDFMSIZ" "DMDHHSZA" "DMDHHSZB" "DMDHHSZE" "DMDHRGND" "DMDHRAGE"
## [37] "DMDHRBR4" "DMDHREDU" "DMDHRMAR" "DMDHSEDU" "WTINT2YR" "WTMEC2YR"
## [43] "SDMVPSU" "SDMVSTRA" "INDHHIN2" "INDFMIN2" "INDFMPIR"table(demo$DMDHSEDU)##
## 1 2 3 4 5 7 9
## 619 511 980 1462 1629 2 23cumsum(table(demo$DMDHSEDU))## 1 2 3 4 5 7 9
## 619 1130 2110 3572 5201 5203 5226length(is.na(demo$DMDHSEDU))## [1] 99716.2.2.2 RNHANES
RNHANES (Susmann (2016)) is another packages for downloading the NHANES data easily. Try yourself.