Chapter 2 Design-based Approach
Before discussing design-based approach, let us review some of concepts related to sampling.
2.1 Sampling
2.1.1 Steps of generalization
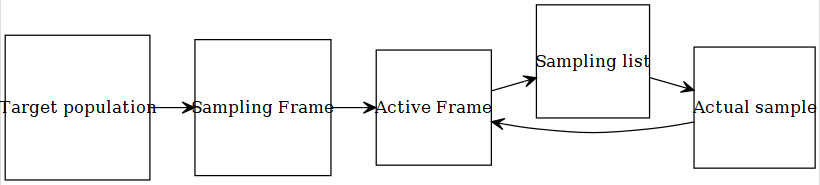
Example: Let us consider CCHS.
- Target population: You think about a
target populationin you PICOT.- Canadian population 12 years of age and over
- Sampling Frame: But all of your target population may not belong to a
sampling framecompiled by a government.- Canadian population 12 years of age and over exluding about 3% population (e.g., aboriginal settlements, canadian Forces, institutionalized, foster care, 2 selected Quebec health regions)
- Active Frame: People that are still reachable
- E.g., not dead or have not moved
- Sampling list
- Prepared from a specific sampling technique (SRS, stratified, cluster, complex)
- Actual sample: people that have responded
- some don’t respond
Note that, results from ‘actual sample’ are generalized to the ‘active frame’. An inference from a sample may not really be generalizable to the target population (strictly speaking).
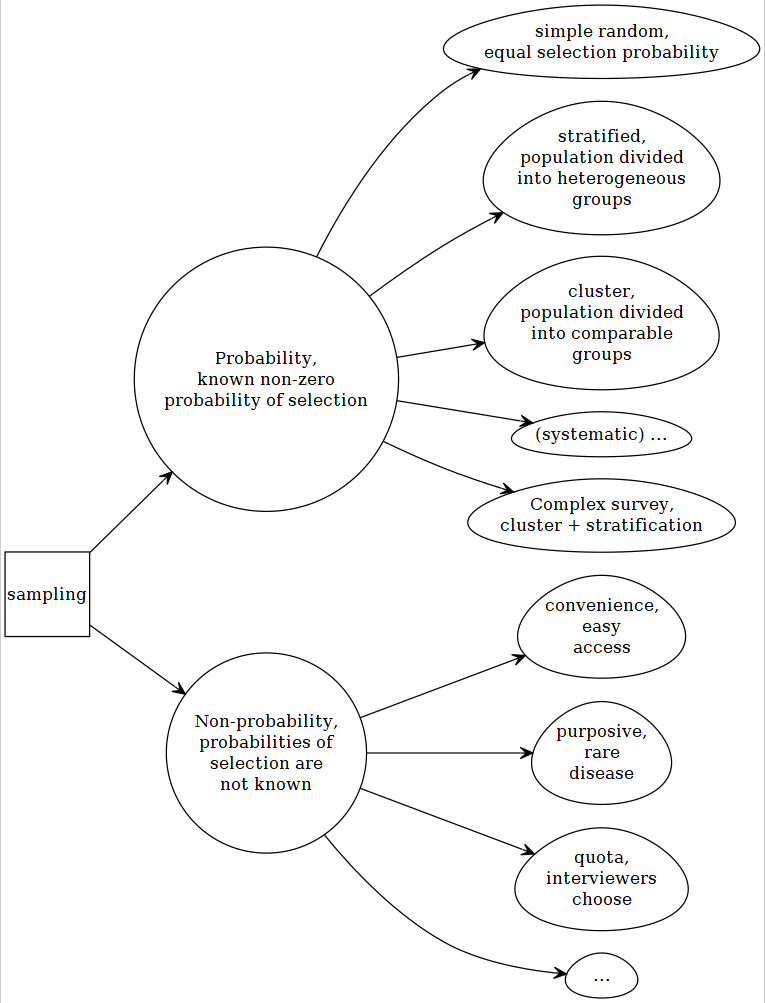
2.2 Statistical inference
2.2.1 Model-based
Most of the statistical techniques we have seen in our pre-requisite courses (SPPH 400, 500) generally assumed that we are dealing with a sample that was obtained from an infinite population. We usually assume that a random process can approximate such data generation process, and the data was collected by a simple random sampling or SRS (everyone has equal opportunity to be selected in the sample). All our conclusions are based on such assumptions. If we are wrong in specifying correct distribution to approximate the data generating process, our subsequent inferences may not be valid anymore.
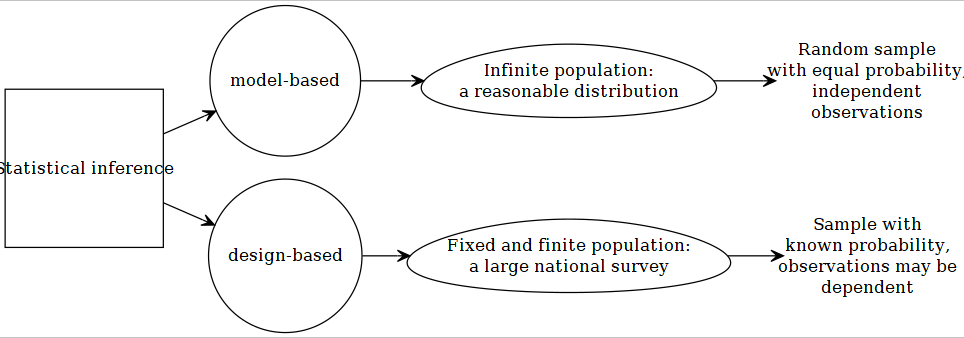
2.2.2 Design-based
Generally, when wide-scale surveys are designed, simple random sampling or SRS may not be feasible for various practical considerations. May be researchers and policy-makers want that a special but small sub-group subjects should be included in our sample (e.g., people suffering from a rare disease), but it is possible that by a SRS scheme, none of the subject from that small subgroup will be included. For convenience of sampling, and for controlling variance, researchers may have to make desicions regarding how the survey needs to collect sample. Researchers may resort to cluster or stratified sampling; or a mix of both (trade-off between cost and precision). Unfortunately, in these cases, equal probability of being selected in the sample is not there any more. Lumley (2011) discussed the following properties for making design-based inference:
- properties needed to get valid estimates
- non-zero probability (\(P_i>0\) for subject i) of being selected in the sample
- every subject has a known probability (\(P_i\)) of being seleted
- properties needed to acieve accuracy of those estimates
- Every pair of subjects must have a non-zero probability (\(P_{ij}>0\) for subjects i and j) of being selected in the sample and
- that probability (\(P_{ij}\)) must be known as well.
2.3 Complex surveys
2.3.1 Design features
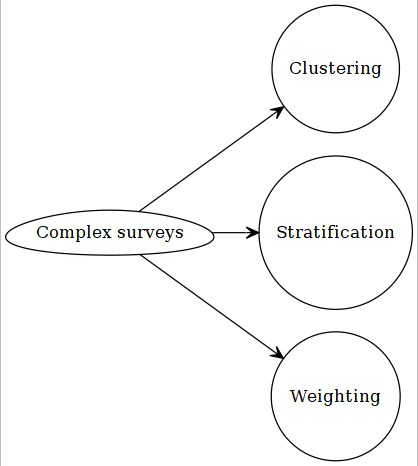
2.3.1.1 Stratification
Considering sub-groups that are sufficiently different from each other with respect to characteristics. Usual examples:
- different geographical location: Manitoba vs. Nunavut
- high income vs. low income
- gender
For each stratum (single unit), sampling is done separately. As we can select sample size from each stratum, we are able to control for variability of the estimates (SE) from each strata as well.
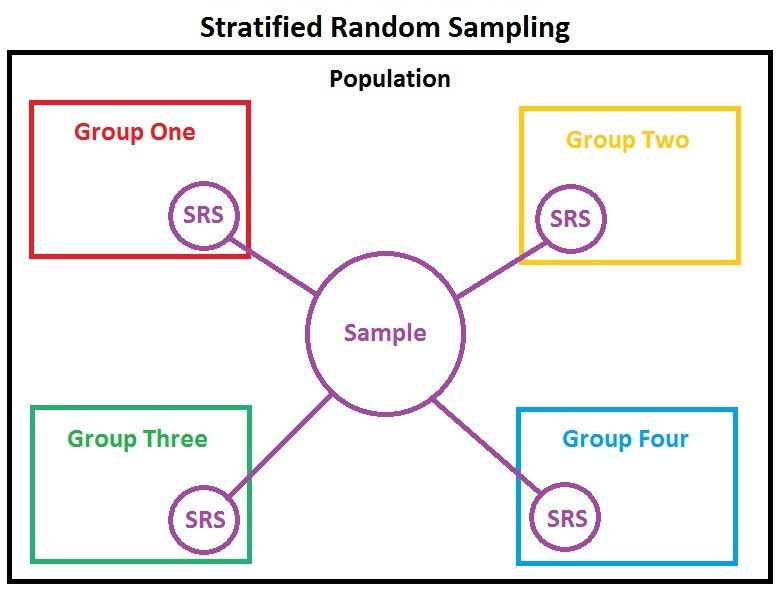
Source: link
2.3.1.2 Clustering
Clustering is done for convenience of data collection, generally. In a nationwide survey, researchers may choose to collect more samples from selected geographic locations. This is generally the case for cost considerations. In doing so, the surveyers don’t have to travel too far, as they could essentially get many neighboring subjects at a much lower cost. An obvious consequence could be that the neighboring subjects may be more correlated with each other compared to subjects who are selected by randomness. This may cause the observations not being independent anymore.
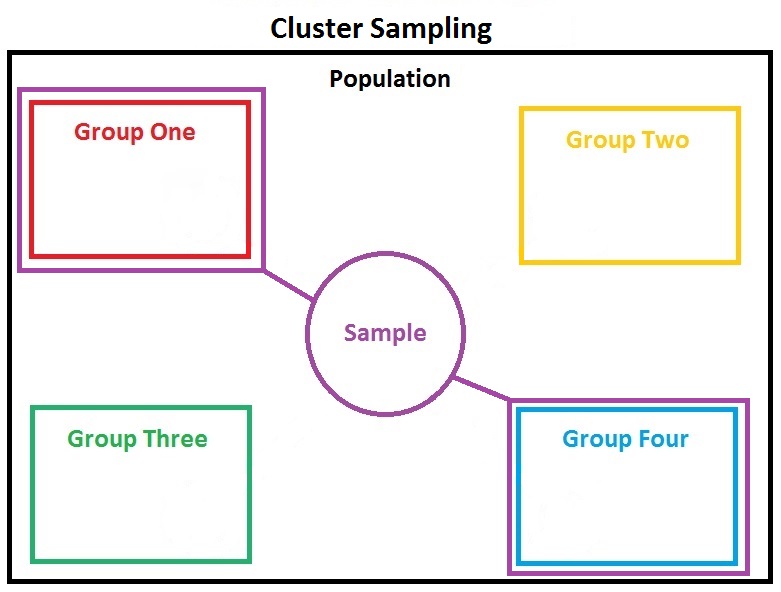
Source: link
2.3.1.3 Weighting
Assume that, in a SRS, a subject is selected in a sample with a probability of \(p_i = 0.04\). This mean, that person is representing \((1/p_i) = (1/0.04) = 25\) subjects in the population. We call this the sampling weight (\(w_i = 25\)). There are other type of weight:
precision weightfrequency weight
but we are not really interested about those in this course in general.
In a complex survey, where we have stratification and clustering, this weight is not as straight-forward becasue, then, it is coming from an unequal probability sampling. As a consequence, not all subjects in the population will have the same probability \((p_i)\) of being included in the sample, and the sampling weights (\(w_i\)) will vary as well (but the probability or weight is known for each subjects).
2.3.2 Design effect
Compared to a SRS, all of the design features of a complex survey, such as, stratification, cluster sampling, and weighting generally influence the SEs of the estimates. Survey researchers use a ratio called design effect, to account for the difference in SEs between a complex survey versus a SRS:
\(DE^2 = \frac{SE^2_{Complex.Survey}}{SE^2_{SRS}}\).