Chapter 5 Demystifying NHANES
5.1 Overview
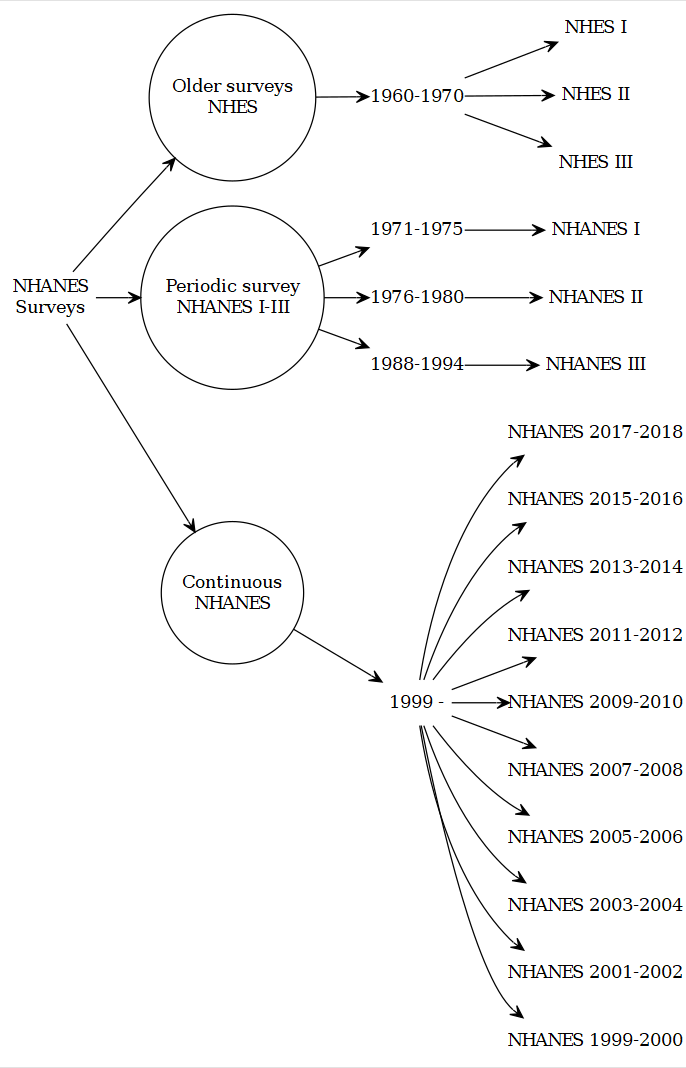
National Center for Health Statistics (NCHS) has been conducting surveys combining interviews with health/laboratory and physical examination studies since 1959. The end-product, recently known as, National Health and Nutrition Examination Surveys (NHANES) provide cross-sectional data of the health and nutrition of the United States population. This information source has been central to formulating nationwide public health policies and practices.
5.3 NHANES datafile and documents
5.3.1 File format
The Continuous NHANES files are stored in the NHANES website as SAS transport file formats (.xpt). You can import this data in any statistical package that supports this file format.
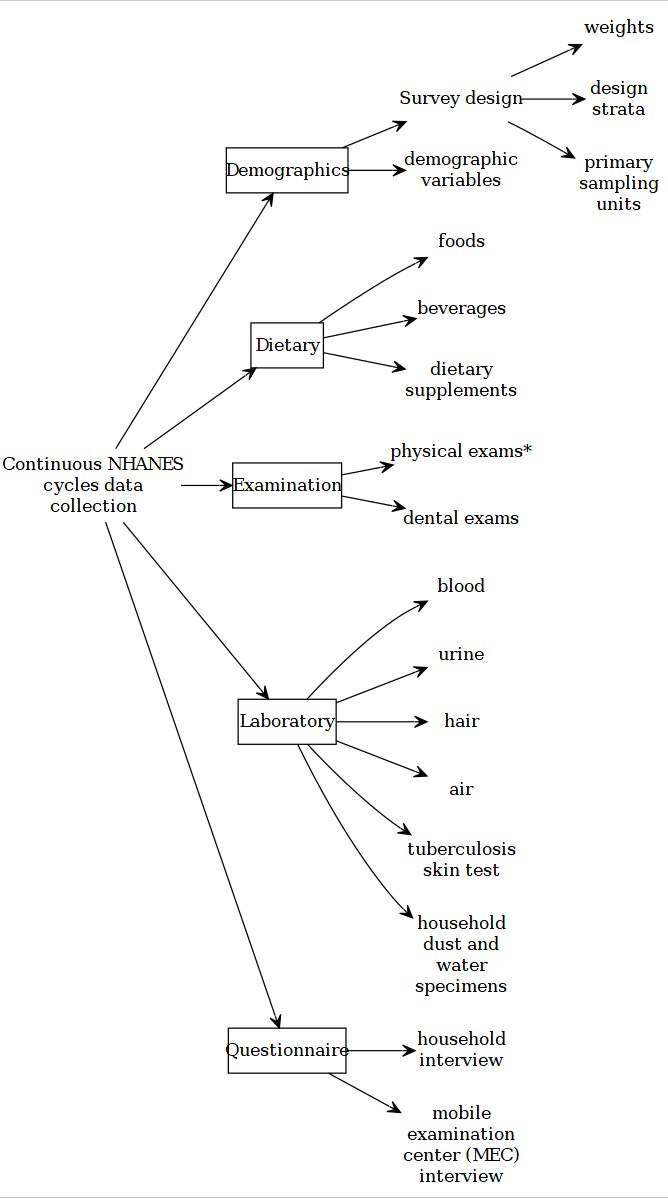
5.3.2 Continuous NHANES Components
Continuous NHANES components separated to reduce the amount of time to download and documentation size:
5.3.3 Public release excludes
The following data have not been released on the NHANES website as public release files due to confidentiality concerns:
- adolescent data on alcohol use,
- smoking,
- sexual behavior,
- reproductive health and drug use
5.3.4 Combining data
5.3.4.1 Different cycles
It is possible to combine datasets from different years/cycles together in NHANES. However, NHANES is a cross-sectional data, and identification of the same person accross different cycles is not possible in the public resease datasets. For appending data from different cycles, please make sure that the variable names/labels are the same/identical in years under consideration (in some years, names and labels do change).
5.3.5 Missing data and outliers
CDC (2018) recommends:
- “As a general rule, if 10% or less of your data for a variable are missing from your analytic dataset, it is usually acceptable to continue your analysis without further evaluation or adjustment. However, if more than 10% of the data for a variable are missing, you may need to determine whether the missing values are distributed equally across socio-demographic characteristics, and decide whether further imputation of missing values or use of adjusted weights are necessary.”
- “If you fail to identify ‘refusal’ or ‘do not know’ as types of missing data, and treat the assigned values for ‘refused’ or ‘do not know’ as real values, you will get distorted results in your statistical analyses. Therefore, it is important to recode ‘refused’ or ‘don’t know’ responses as missing values (either as a period (.) for numeric variables or as a blank for character variables).”
- “Outliers with extremely large weights could have an influential impact on your estimates. You will have to decide whether to keep these influential outliers in your analysis or not. It is up to the analysts to make that decision.”
5.4 Exercise (web)
- More information about NHANES design
- Visit US CDC and do a variable keyword search based on your research interest (e.g., arthritis).